Regression
Analysis - Confidence Interval for Measured X (Interpolation)
Consider the case where a number of observations (n) are used to calibrate an instrument. The dependent quantity (xi) is varied and the independent quantity (yi) is measured with the instrument. Now we may use the instrument to measure the y value of an “unknown” sample. From this we compute the x value of the sample. We wish to report the value of the unknown with its confidence level; we wish to report a value with the format x = 1.234 ± 0.345.
We would begin by fitting the calibration data to a line of best fit – generally a linear relationship (y = mx + b) is used. We may now use x = (y – b)/m to discover the value of the unknown sample which records a value of y on the instrument. Frequently we would make a number of repeated measurements of y with the unknown sample. Let k be the number of repeated measurements (this may, of course, be 1)
However, there is an uncertainty associated with the calibration curve and we wish to report a confidence interval with the computed x value. The confidence interval for the predicted x value for a given value of the independent variable x is computed using either:
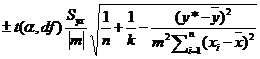 or
or 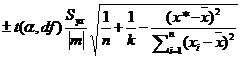
where t is the critical t statistic, Syx the standard error of the estimate, y* the average measured value of y measurements for the unknown sample, x* the computed value of x = (y – b)/m. An example is shown in the diagram below. Click here to open the Excel file.
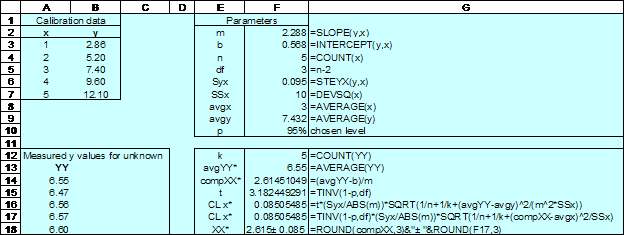
The labels x, y and YY are used to name the data A3:A7, B3:B7 and A14:A18, respectively. The labels in E2:E16 are used to name the cells to their right.
The cells F2:F9 are used to compute values from the calibration data (A1:B7) while in cells F12:F18 we computed values associated with data on the “unknown” sample. Note that the experimenter made 5 duplicate measures on the sample. In F16 and F17 we have two formulas to show that the equation shown above are indeed equivalent. The symbol ± is produced with the keystrokes ALT+0177; the numbers must be typed on the numeric keypad.
