Topic 7 - Hashing
We have seen most of the search tree that you can encounter in CS.
We will now see an ADT that you already used before the hash table ADT.
Hash tables only have a subset of the search trees operations:
Insertions
Deletions
Find
All the operations that require any ordering information among the elements are not supported.
General Idea
A hash table can be seen as an array containing elements.
The elements are composed of two parts:
The key.
The element itself.
Another important element of the table is the table’s size. We will see that the size is crucial part of the ADT.
How does it work?
Each key is mapped into some number in the range of 0 to \(\text{TableSize}-1\).
The mapping is called a hash function.
The function must be simple to compute
And should ensure that a key is unique
Example
Imagine that we want to use a Hash Table to store names.
We could obtain the following table:
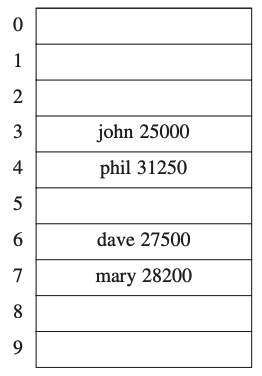
In this table John has to \(3\), Phil to \(4\).
Important
This example shows a perfect case. Some key could have the same hash!
Hash Function
This hash function is the most important part of the ADT.
Activity
Think about a possible function.
Discuss it with your neighbours.
A simple case
Consider a hash table that need to store integers.
Then, a simple hash function could be
Activity
Is it always working for integers? * If yes, prove it. * Otherwise, show a counterexample.
Consider a table of size 10, if you have multiple integers ending with a zero, then it will not work.
To counter this, we always ensure that the size is prime. It distributes the keys evenly.
More general case
Usually keys are strings.
With strings keys the hash function is more complex and must be chosen carefully.
We will consider three examples of hash functions.
First Example
Activity
Write a hash function that takes a string as key and hash it by adding the ASCII value of each char and return the modulo.
int hash(const string &key, int tableSize){
}
The table size needs to be large enough.
Consider a size of \(10 007\)
Suppose the keys have a size of eight or less.
The hash will calculate only values between 0 and \(1 016\), which is \(127\times 8\).
It does not distribute the values evenly.
Second Example
We can consider a second example.
Consider that the key will have at least three characters.
The value 27 represents the number of letters in the English alphabet (plus the blank).
729 is \(27^2\).
We can implement the following function:
int hash(const string &key, int tableSize){
return (key[0] + 27*key[1] + 729*key[2]) % tableSize;
}
It could work if the word in English are random, but they are not.
We could imagine there are \(26^3 =17576\) possible combinations of three characters.
In reality only \(2851\)!
Only 28 percent of the table can actually be hashed, and increasing the size of the table doesn’t change anything.
Third Example
The following code implement the Horner’s method.
unsigned int hash(const string &key, int tableSize){
unsigned int hashVal = 0;
for (char ch: key){
hashVal = 37 * hashVal + ch;
}
return hashVal % tableSize;
}
It calculates a polynomial function of 37 to an \(n\) being the size of the string:
Activity
Is it a good hash function?
Separate Chaining
How are we dealing collision?
We can have a good has function, but it can always create a collision even if it’s uncommon.
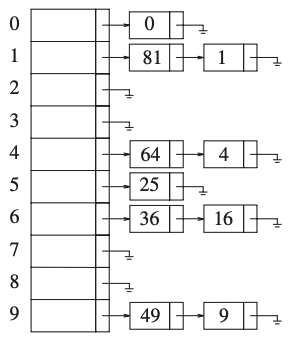
A first strategy is known as separate chaining.
The idea
We represent the HashTable by a vector (from the STL) of list.
When a key has a hash that collides we add the key to the list corresponding to the vector index.
If it’s not very clear, here is an illustration:
Activity
Complete the interface of the class.
Create the constructor
Create the insert and remove method
Create the private data members.
1template <typename HashedObj>
2class HashTable
3{
4public:
5
6private:
7
8 void rehash();
9 size_t myhash(const HashObj &x) const;
10
11}
Hashing
Now we need to implement the hash function.
In C++, it is usually done with a function object template:
template <typename Key>
class hash{
public:
size_t operator() (const Key &k) const;
};
It is already implemented for basic types such as int or string.
Example
The code given in the third example would be written like this:
1template <>
2class hash<string>{
3public:
4 size_t operator() (const string &key){
5 size_t hashVal = 0;
6
7 for(char ch: key){
8 hashVal = 37*hashVal+ch;
9 }
10
11 return hashVal;
12 }
13};
The type size_t is an unsigned integer type that represents the size of an object.
It guarantees that it can store an array index.
We can finally see how to implement myhash().
size_t myhash(const HashObj &x) const{
static hash<HashedObj> hf;
return hf(x) % theLists.size();
}
Example
We will see a practical example.
Consider the following class Employee:
1class Employee{
2public:
3
4 Employee(string name, double salary, int seniority):
5 name{name}, salary{salary}, seniority{seniority}
6 {
7
8 }
9
10 const string& getName() const{
11 return name;
12 }
13
14 bool operator==(const Employee &rhs) const{
15 return getName() == rhs.getName();
16 }
17
18 bool operator!=(const Employee &rhs){
19 return !(*this == rhs);
20 }
21
22private:
23
24 string name;
25 double salary;
26 int seniority;
The first is to implement the hash function object template operator().
Activity
Implement the hash function object.
Implementation
There are 4 methods that need to be implemented:
makeEmpty
contains
remove
insert
makeEmpty
The method is simple, for each list in the vector, clear the list.
contains
It is also simple.
You start by hashing the object.
Then, you get the list in the vector.
Finally, you try to find the element in this list.
remove
The first steps are the same that for contains.
If the element is not found, return false.
Otherwise, erase the element, reduce currentSize by 1 and return true.
insert
The first steps are the same that for contains.
If the element is not inside the list, insert it.
Increase currentSize by 1, and if currentSize is greater than the size of the list rehash.
Finally return true.
Activity
Implement these methods.