1. Multi-armed Bandit
In this lab, you will test the impact of \(\epsilon\)-greedy action selection compared to a greedy action selection.
1.1. Setting up
1.1.1. Virtual environment
First you will set up a virtual environment for python.
Create a folder for the labs.
Inside your new folder, open a terminal and enter the following command:
python3 -m virtualenv CSCI_531
It should create a new folder CSCI_531.
Activate the virtual environment, by entering the following command:
source ./CSCI_531/bin/activate
Important
Every lab you will need to activate the virtual environment before using python!
1.1.2. Python libraries
Now you need a few libraries.
The main library that we will use is Gymnasium .
To install it use:
pip install gymnasium
1.2. Gym
1.2.1. What is a Gym environment
Gymanisum provides tools to create Reinforcement Learning environments.
The environments are implemented using the same structures:
It allows to implement algorithms that works for all Gym environments.
Helps organize and debug your environment.
1.2.2. Custom environment
One thing we want to do is creating our own custom environment.
1.2.2.1. Environment
Each class inherits from
gymnasium.Env.Then we need to specify
self.action_space:It is the mathematical representation of the actions the agent can execute.
For example, if the agent can move left or right:
We have two actions.
The actions are discrete.
We will define the action space as
Discrete(2) # {0, 1}.Action 0 will be left and 1 will be right.
Example
An example of a custom environment with an action space of two discrete actions.
import gymnasium as gym
from gymnasium.spaces import Discrete
class MyEnv(gym.Env):
def __init__(self):
self.action_space = Discrete(2)
1.2.2.2. Step
Once the environment is created, we need to define how the agent will interact with it.
It is done with the method
step(self, action).action: Action selected by the user or (AI).Use this function to modify the environment if necessary, like the position of a robot, etc.
It returns 5 parameters:
observation
reward
terminated
truncated
info
For now, we only care about the reward.
Example
An example of a custom environment with the step function defined.
import gymnasium as gym
from gymnasium.spaces import Discrete
class MyEnv(gym.Env):
def __init__(self):
self.action_space = Discrete(2)
def step(self, action):
reward = # How your reward is calculated.
return [], reward, False, False, {} # Only reward is important for now, put everything else as default value.
1.3. 10-armed bandit
You need to implement the 10-armed bandit.
Create a class
tenBanditas a Gym environment.Define the action space.
Initialize each arm.
Each arm \(a\) has an optimal value \(q^*(a)\) that you will sample in a normal distribution of mean \(0\) and variance \(1\).
Create a function
step()that simulate an arm being selected.When a user selects an arm it returns a value sampled from a normal distribution of mean \(q^*(a)\) and variance \(1\).
1.4. Simple algorithm
Now you need to implement the algorithm seen in class (Multi-armed bandit).
Create a function
e_greedy(bandit, e, T)bandit: is the class bandit created before.e: is the \(\epsilon\).T: is the number of steps.
The function should return:
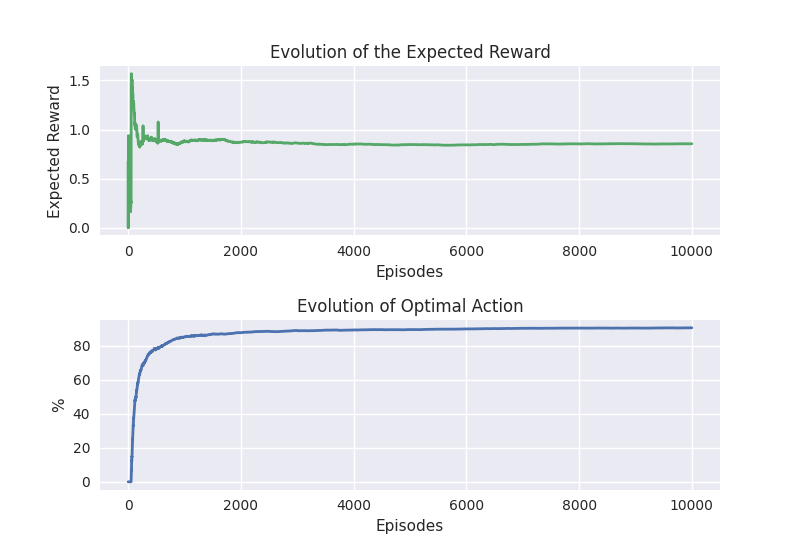
The evolution of the expected rewards.
The evolution of the percentage of optimal action.
1.5. Experiments
Combine everything to run different experiments.
Compare a greedy (\(\epsilon = 0\)) action selection with an \(\epsilon\)-greedy action selection(\(\epsilon = 0.1\))
Compare different \(\epsilon\)-greedy, to show the impact of \(\epsilon\).
Plot the results
Example
An example with \(\epsilon = 0.1\).