4. Markov Decision Process
Reinforcement Learning has its foundation in the formal problem of Markov Decision Process (MDP).
Markov Decision Process is a mathematical model formalizing sequential decision-making.
Problems in which we take multiple consecutive actions.
Actions have consequences on the future states and future rewards.
Important
MDPS involve delayed rewards, so it involves the need to trade off immediate and future rewards.
Activity
How is it different from multi-armed bandit?
Reinforcement learning and Markov decision processes are so linked that an MDP is just and idealized form of RL.
In an MDP, we know the problem perfectly and we try to find the optimal solution.
4.1. Markov Decision Process Definition
Markov decision processes formalize how an agent learn to achieve a goal.
The agent can interact with the environment.
The environment comprises everything outside the agent.
When the agent interact with the environment, the environment changes.
The agent will then consider a possible new action depending of the new situation.
It repeats until the problem is solved.
Definition
Formally, a MDP is defined as a tuple \((S,A,T,R)\):
\(S\) is the finite set of states \(s \in S\),
\(A\) is the finite set of action \(a \in A\),
\(T: S\times A \times S \rightarrow [0,1]\) is the transition function,
\(R: S\times A \rightarrow \mathbb{R}\) the reward function.
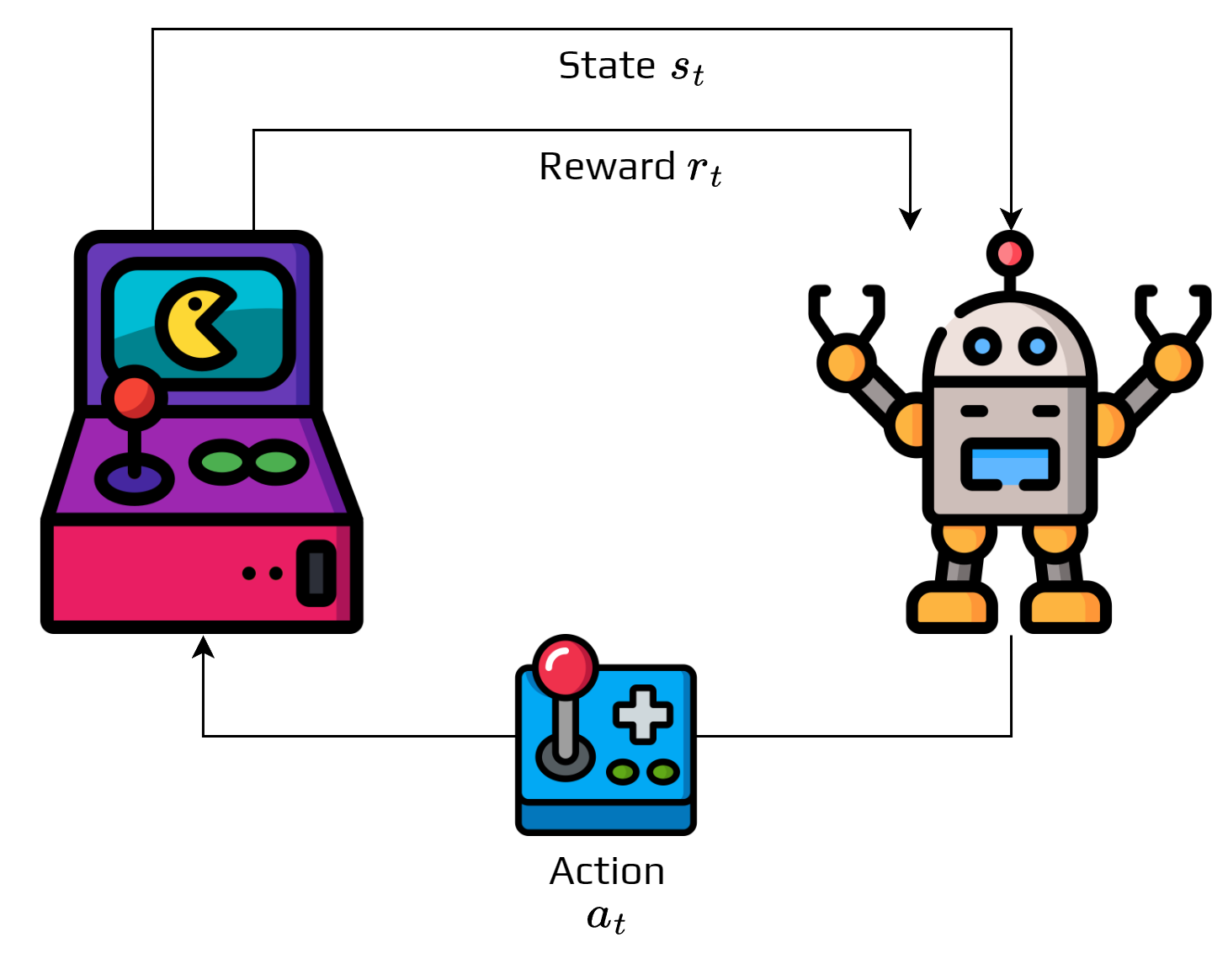
The figure represents the agent-environment interaction.
At each time step \(t\), the environment is in a state \(s_t\).
Based on this state, the agent must select an action \(a_t \in A\).
After executing the action:
the environment is in a new state \(s_{t+1}\),
the agent receives a reward \(r_t\).
It generates a sequence of states and actions:
This sequence is called a trajectory.

Activity
Find a problem that could be represented as a MDP.
Specify how you would define the state and actions.
4.1.1. Transition function
After executing \(a_t\) in \(s_t\), a new state \(s_{t+1}\) is generated.
The new state \(s_{t+1}\) is generated following a discrete probability distribution:
This conditional probability is the transition function of the MDP.
Note
Remind that for all state \(s\in S\) and actions \(a\in A\) we have:
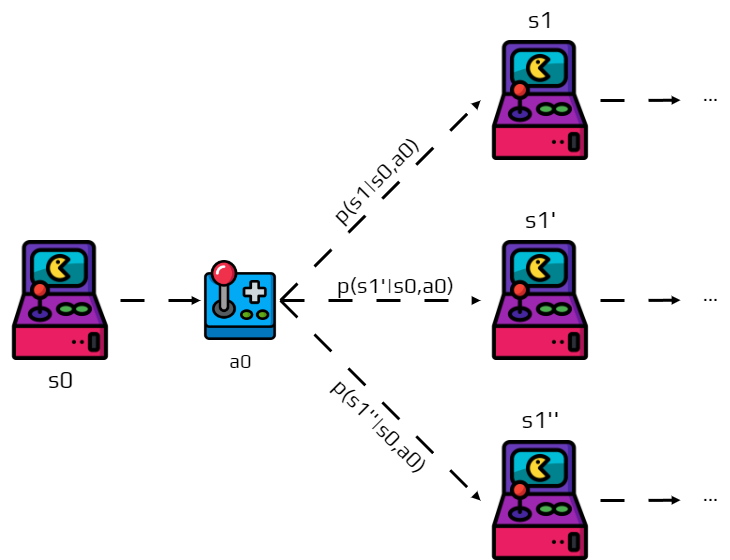
If you look at the transition function, we can note something.
The probability of \(s'\) depends only on state \(s\) and action \(a\).
We call this the Markov property.
Definition
All information about past interactions necessary to predict the future state must be contained in the current state.
Activity
Try to explain why this is important for an MDP.
4.1.2. Reward function
Finally, the reward for doing an action \(a_t\) in \(s_t\) is given by a function \(r(s,a)\).
4.2. Applications and implications
This framework is popular, because it’s abstract and flexible.
You can model lot of different problems with a single framework.
Algorithms to solve it can be reused for any problems if modelled as a MDP.
Actions:
Low-level actions: Voltage input for robots’ actuators (wheels, arms,etc.).
High-level actions: Direction where the robot needs to move (Up, Down, Right, Left).
Time steps:
In real time: a time interval between actions.
Abstract: Player turn.
State representation:
The state can be very low level. For example, the sensor reading from a robot.
Something high-level like the position in the maze.
Or totally abstract, like the agent being in a state of not knowing if it’s raining outside.
This is why you can find RL in different fields:
Robotics
Economics
NLP
IoT
4.3. Defining goals and rewards
We use RL for something, usually we want to solve a problem.
To solve a problem you have an objective, a goal.
In reinforcement learning (and MDP) the goal is not directly defined.
You can verify in the MDP definition, the goal is mentioned nowhere.
Instead of defining the goal directly, we use the reward function to do it.
After each action \(a\), the environment send to the agent a reward \(r\in \mathbb{R}\).
So the goal for the agent is to maximize the long term cumulated reward.
Consequently, you need to design a reward function that leads to the concrete goal.
It can seem limiting, but it’s very flexible in practice.
Example
Consider a robot in a maze.
It needs to learn how to escape quickly.
The most common practice is to give a reward of \(-1\) per action executed until the robot escape.
Activity
Why do you think this reward function works well to achieve the goal?
Discuss another possible reward function.
The agent will maximize the cumulated reward, so we must provide a reward function that if maximized lead to the goal we want.
Activity
What reward function would you use for TicTacToe?
Consider a game of chess; what do you think about giving rewards for taking the opponent’s pieces?
Important
The reward must communicate what the agent needs to achieve not how to achieve it.