Introduction#
What is Reinforcement Learning (RL)?#
Reinforcement learning is what to do to maximize a reward.
We can give a more “formal” definition.
Definition 1 (Reinforcement Learning)
Reinforcement Learning is calculating a function that maps situations to actions.
We said that we want to maximize a reward, but what is a reward?
Activity
Try to explain what a reward is.
To maximize a reward the learner can do different actions.
If the learner was passive, it could not maximize anything.
Usually, the learner start with no prior knowledge about what action it should do.
Activity
What would you do to maximize a reward if you had no idea which action you should do?
Key Concepts - The Basics#
Reinforcement learning has two main characteristics:
Trial-and-error search: Learning by trying things and seeing what works
Delayed rewards: Actions now may have consequences much later
Why these matter:
Trial-and-error means no teacher provides “correct” answers - you learn by experience
Delayed rewards means you must connect actions to outcomes that happen later
We’ll explore these concepts in detail later, but first let’s see the bigger picture of this learning approach.
Warning
Reinforcement learning is a name that regroups different concepts:
It’s a type of problem.
It’s also a class of solution methods.
And it’s the field that study the two previous points as well.
You need to understand the distinction.
Now that you understand these basic characteristics, let’s zoom out to see the complete picture.
What is the Reinforcement learning problem? (Simplified)#
The reinforcement learning problem is an idea coming from dynamical system theory.
And more specificaly from the Markov Decision Processes.
The basic ideas are:
A learning agent must sense the state of the environment.
The agent must be able to take actions that affect the state.
It must have a goal or goals relating to the state of the environment.
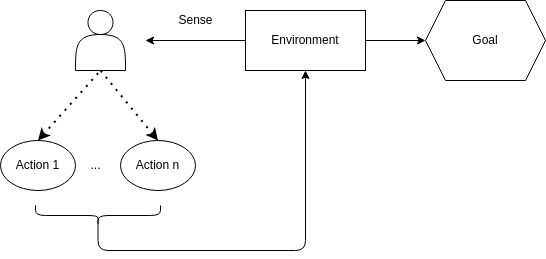
This simple agent-environment loop might look basic, but it powers some of the most impressive AI breakthroughs.
Why Reinforcement Learning Matters#
Now that you understand the basics, let’s see why RL has become so important:
Real-World Success Stories#
Game Playing: AlphaGo defeated world champions, mastering strategy through self-play
Autonomous Systems: Self-driving cars make split-second decisions in complex environments
Finance & Trading: Systems optimize investment decisions over time under uncertainty
What Makes These Problems Special?#
Traditional AI approaches fail because these problems require:
Learning without a teacher - no dataset of “perfect” decisions exists
Handling delayed consequences - actions now affect outcomes much later
Adapting to change - environment responds to your actions
Balancing exploration vs exploitation - try new things vs use current knowledge
You might wonder: why couldn’t traditional machine learning solve these problems? Understanding what RL is requires understanding what it’s not.
What Reinforcement learning is not?#
Understanding RL is easier when we compare it to other learning paradigms:
Learning Type |
Data Required |
Feedback Type |
Goal |
Example |
When It Fails |
|---|---|---|---|---|---|
Supervised |
Labeled examples |
Immediate correct answers |
Predict/classify |
Email spam detection |
No “correct” action dataset available |
Unsupervised |
Unlabeled data |
No feedback |
Find patterns |
Customer segmentation |
No clear objective function |
Reinforcement |
Environment interaction |
Delayed rewards |
Maximize cumulative reward |
Game playing |
Need real-time interaction |
Key Differences Explained#
Why supervised learning fails for RL problems:
No perfect dataset: There’s no collection of “correct” actions for every situation
Context dependency: The best action depends on long-term consequences, not just current state
Interactive nature: The environment changes based on your actions
Why unsupervised learning isn’t enough:
No objective: Finding patterns doesn’t tell you which actions are good
No feedback: You can’t improve without knowing if you’re doing well
Activity
Looking at the table above:
Why can’t you use supervised learning to learn chess strategy?
What would unsupervised learning find in a chess game, and why isn’t that sufficient?
Give an example of a problem where you’d need each type of learning.
The challenges of reinforcement learning.#
Reinforcement learning faces unique challenges that make it different from other machine learning approaches:
1. The Exploration-Exploitation Trade-off#
This is the fundamental challenge in RL:
Strategy |
Description |
Pros |
Cons |
Example |
|---|---|---|---|---|
Exploitation |
Use current knowledge to get reward |
Immediate gains |
Miss better options |
Always go to your favorite restaurant |
Exploration |
Try new actions to learn |
Discover better options |
Short-term costs |
Try a new restaurant (might be bad) |
Balance |
Mix both strategies |
Long-term optimal |
Complex to implement |
Sometimes try new places, sometimes stick to favorites |
Agent Decision Process:
1. Agent faces decision
├── Action A: Known good reward (reliable)
└── Action B: Unknown reward (risky)
2. Two strategies:
├── EXPLOIT: Choose A → Get expected reward (but miss learning)
└── EXPLORE: Try B → Learn about B (might find better option)
3. The dilemma:
• Pure exploitation = stuck with current best
• Pure exploration = never use what you learn
• Need balance for optimal long-term performance
Key insight: You can’t do only one strategy - pure exploitation gets stuck in local optima, pure exploration never uses what you learn.
2. The Whole Problem Challenge#
Complete system: RL considers the entire problem from start to finish
Goal-seeking agent: Must actively pursue objectives, not just respond to inputs
Uncertainty handling: Must operate effectively despite incomplete information about the environment
Activity
Think of a time when you had to balance exploration vs exploitation in real life. How did you decide when to try something new vs stick with what you know?
Understanding these challenges prepares us to examine what makes RL systems work. Every RL agent relies on the same core building blocks.
Elements of reinforcement learning#
Every RL system consists of four key components that work together:
Activity
What are the two elements we talked about that compose reinforcement learning?
The Four Core Elements#
Element |
Purpose |
Think of it as… |
Required? |
|---|---|---|---|
Policy |
Decision maker |
The brain that chooses actions |
Essential |
Reward Function |
Goal definition |
The scoring system |
Essential |
Value Function |
Long-term predictor |
The strategic advisor |
Essential |
Model |
Environment simulator |
The crystal ball |
Optional |
1. Policy - The Decision Maker#
Definition 2 (Policy)
A policy is a function that maps each state to an action.
Click to explore Policy details
What it does:
Defines the behavior of an agent at any given time
Core of the RL agent - determines all actions
Can be deterministic (same action every time) or stochastic (probabilistic)
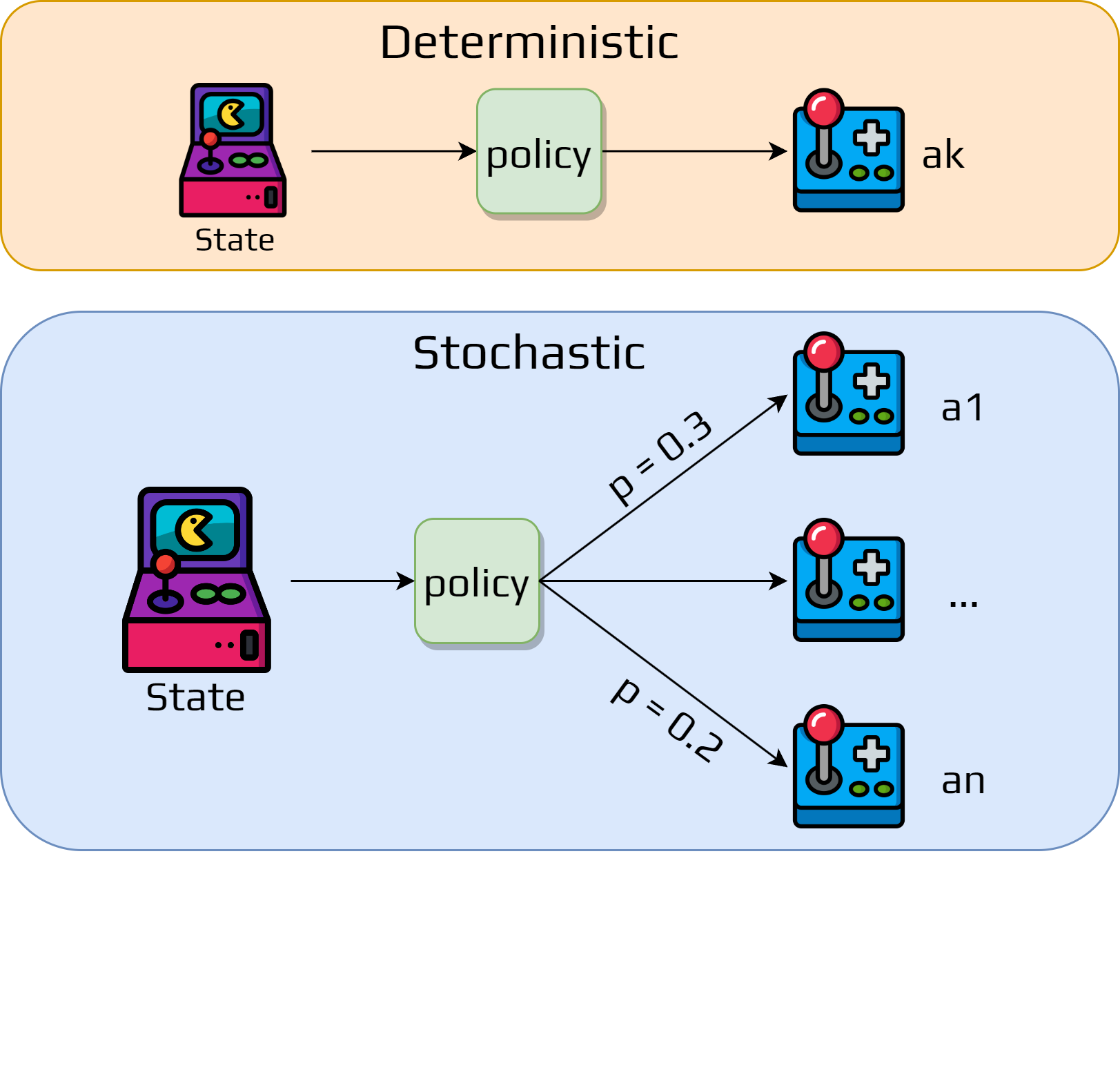
Examples:
Chess: “If opponent threatens my queen, move it to safety”
Trading: “If price drops 5%, sell 20% of holdings”
Navigation: “If obstacle ahead, turn left”
2. Reward Function - The Goal Definition#
Definition 3 (Reward)
A reward is a value returned by the environment at a time step \(t\).
What it does:
Defines the goal of the RL problem
Provides immediate feedback for actions
Agent’s objective: maximize total reward over time
Examples:
Game: +10 for winning, -1 for losing, 0 for draw
Robot: +1 for forward movement, -10 for collision
Trading: +profit for good trades, -loss for bad ones
3. Value Function - The Strategic Advisor#
Definition 4 (Value Function)
A value function is a function returning for each state the total expected reward starting from this state.
What it does:
Estimates long-term expected reward from each state
Helps agent think strategically, not just about immediate rewards
Much harder to determine than immediate rewards
Key insight: We seek actions that lead to states with higher value, not higher immediate reward.
Activity
Reward vs Value - Which would you choose?
State A: immediate reward = 100, long-term value = 3
State B: immediate reward = 1, long-term value = 5
Why might State B be better despite lower immediate reward?
Examples:
Chess: Sacrificing a piece (negative reward) to gain better position (higher value)
Investment: Spending money on education (cost now) for better career (future value)
Medicine: Taking bitter medicine (negative reward) for health (long-term value)
4. Model - The Crystal Ball (Optional)#
Definition 5 (Model)
The model of the environment is the representation of the dynamic of the problem.
Click to explore Model details
What it does:
Predicts what happens next: given current state and action, what’s the next state and reward?
Allows agent to plan ahead and simulate different strategies
Not always available or practical to learn
Two RL Approaches:
Type |
Has Model? |
Characteristics |
Examples |
|---|---|---|---|
Model-based |
✅ Yes |
Can plan ahead, simulate scenarios |
Chess engines, route planning |
Model-free |
❌ No |
Learn directly from experience |
Most game AI, trial-and-error learning |
Examples:
Chess: Model knows all game rules and can simulate moves
Stock Trading: Model predicts market reactions to events
Robot Navigation: Model predicts where robot will be after moving
These four elements work together like a team - each has a specific role, but their real power comes from how they interact in the learning process.
Summary#
You now understand the core building blocks of reinforcement learning! From our coffee shop example to these fundamental elements, you’ve seen how RL systems learn through experience.
Current Limitations & Assumptions#
RL is powerful but has important limitations to keep in mind:
State Representation Challenge#
Challenge |
Description |
Impact |
Example |
|---|---|---|---|
State Design |
How to represent the current situation |
Huge impact on learning speed |
Raw pixels vs processed features |
State Space Size |
Too many possible states |
Learning becomes very slow |
Chess: 10^43 possible positions |
Partial Observability |
Can’t see everything relevant |
Must work with incomplete info |
Poker: can’t see opponents’ cards |
Key Points:
State is everything: The quality of state representation determines learning success
Not magic: RL assumes you can define reasonable states, actions, and rewards
Computational limits: Large state spaces require advanced techniques
Design matters: How you frame the problem affects what the agent can learn
Activity
Think about teaching someone to drive:
What information (state) do they need to make good decisions?
What if they could only see through a small window - how would this affect learning?
How would you define “good driving” as rewards?
What’s Next?#
You now have a solid foundation in reinforcement learning concepts! Here’s what we’ve covered:
Core RL Concepts: Trial-and-error learning with delayed rewards
Key Elements: Policy, rewards, values, and models
Main Challenge: Balancing exploration vs exploitation
Why RL Matters: Real-world applications where traditional AI fails
Up Next: Multi-Armed Bandits
Remember how you had to decide which coffee shops to try? We’ll formalize this exact problem as “multi-armed bandits” - the perfect stepping stone from our simple example to more complex RL scenarios.
For Advanced Readers
If you want to dive deeper into theoretical foundations, detailed delayed rewards analysis, and advanced case studies like AlphaGo, check out the Advanced RL Concepts Appendix after completing the main course content.