Dynamic Programming#
From Theory to Practice: Computing Optimal Policies#
In the previous sections, we learned:
How to model problems as MDPs
Why we need policies and value functions
What optimal policies and value functions look like mathematically
The Remaining Challenge: How do we actually compute these optimal policies and value functions?
The Approach Menu: There are various computational approaches:
Dynamic programming (requires complete knowledge of MDP)
Monte Carlo methods (learns from experience)
Temporal difference learning (combines both approaches)
Why Start with Dynamic Programming:
Conceptual Foundation: Establishes the core principles used in all RL algorithms
Theoretical Clarity: Shows exactly what we’re trying to approximate in other methods
Practical Utility: Works perfectly when we know the MDP completely
Activity
What do we need to calculate to obtain the optimal policies?
Give the formulas.
Policy Iteration: The Intuitive Approach#
The core idea is simple: start with any policy, then repeatedly improve it until we can’t make it any better. This involves two alternating steps: policy evaluation (calculating how good the current policy is) and policy improvement (updating the policy based on these values).
Each improvement step is guaranteed to make the policy better (or keep it the same if already optimal). The algorithm follows this flow:
Random Policy → Evaluate → Improve → Evaluate → Improve → ... → Optimal Policy
Policy Evaluation#
Given a fixed policy \(\pi\), we want to compute its value function \(v_\pi(s)\) for all states. This presents us with the Bellman equation:
This equation is circular—the value of state \(s\) depends on the values of future states \(s'\). We solve this through iterative approximation, starting with initial guesses and improving them until they stabilize.
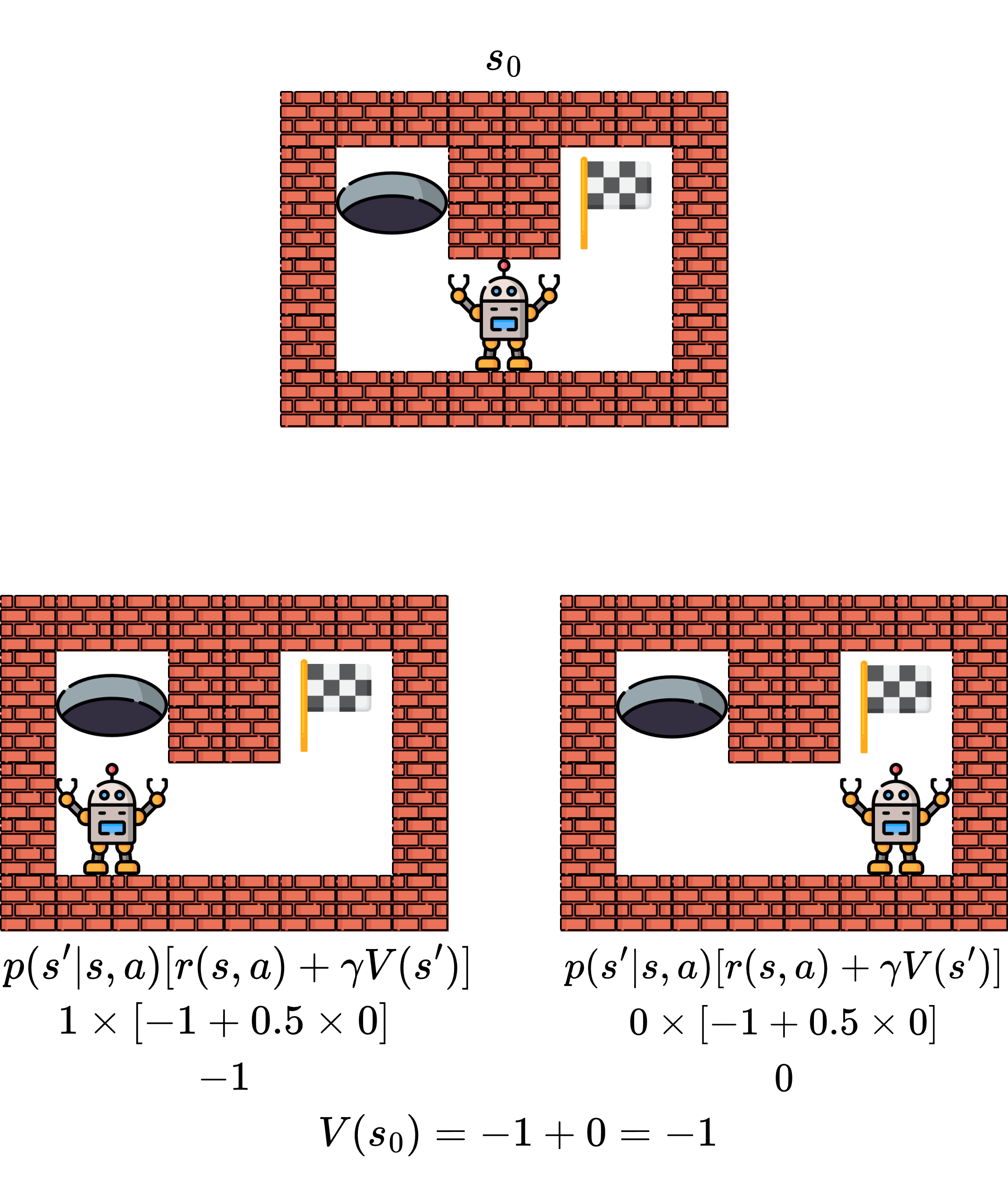
The process begins by setting initial value estimates \(v_0(s)\) (often all zeros). Then, for each iteration \(k\), we compute new estimates: $\(v_{k+1}(s) = \sum_a\pi(a|s)\sum_{s'}p(s'|s,a)\left[ r(s,a) + \gamma v_k(s') \right]\)$
We continue until values stop changing significantly. Each iteration gives us a better approximation, and eventually the values converge to the true \(v_\pi\). Intuitively, we’re propagating value information backwards through the state space—good states make their neighbors more valuable.
Of course at each step you need to calculate \(v_k(s)\) for every state \(s \in S\). Put in an algorithm we obtain:
Algorithm 2 (Policy Evaluation)
\( \begin{array}{l} \textbf{Inputs}:\\ \quad\quad \pi\ \text{the policy to evaluate}\\ \quad\quad \theta\ \text{A threshold}\\ \textbf{Initialize}: \\ \quad\quad V(s) \in \mathbb{R}, \text{arbitrarily, for all } s \in S,\ \text{except}\ V(terminal)=0 \\ \textbf{Loop}:\\ \quad\quad \Delta\leftarrow 0\\ \quad\quad \textbf{Foreach}\ s\in S:\\ \quad\quad\quad\quad v \leftarrow V(s)\\ \quad\quad\quad\quad V(s) \leftarrow \sum_a\pi (a|s)\sum_{s'\in S}p(s'|s,a)\left[r + \gamma V(s')\right]\\ \quad\quad\quad\quad \Delta \leftarrow \max (\Delta, |v-V(s)|)\\ \textbf{until}\ \Delta < \theta\\ \end{array} \)
Example 2
We will consider the following problem, initial policy, and initial value function.
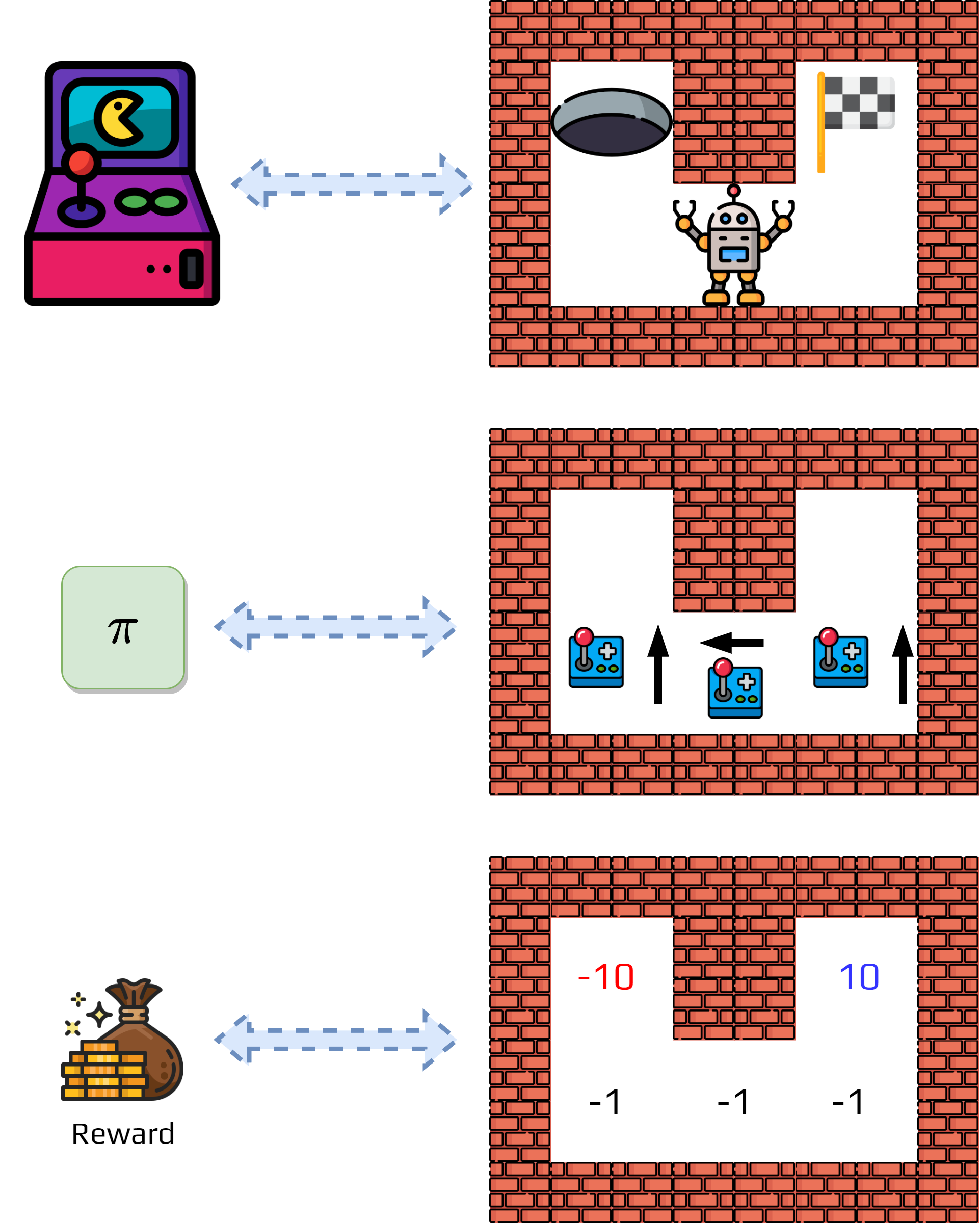
Now we estimate the value function using the formula.
Policy Improvement#
Given a policy \(\pi\) and its value function \(v_\pi\), we can find a better policy. If we know how valuable each state is, we can improve our policy by being greedy with respect to these values.
For each state \(s\), we examine all possible actions. For each action \(a\), we calculate what would happen if we took that action: $\(q_\pi(s,a) = \sum_{s'}p(s'|s,a)\left[r(s,a) + \gamma v_\pi(s')\right]\)$
The value \(q_\pi(s,a)\) tells us: “If I take action \(a\) in state \(s\), then follow my current policy, what’s my expected return?” If \(q_\pi(s,a) > v_\pi(s)\), then action \(a\) is better than what our current policy suggests, so we should update our policy to choose action \(a\) in state \(s\).
The improvement step creates a new policy \(\pi'\) where: $\(\pi'(s) = \arg\max_a q_\pi(s,a) = \arg\max_a \sum_{s'}p(s'|s,a)\left[r(s,a) + \gamma v_\pi(s')\right]\)$
Theorem 1 (Policy improvement)
Let \(\pi\) and \(\pi'\) being any pair of deterministic policies such that, for all \(s\in S\),
Then the policy \(\pi'\) must be as good as, or better than \(\pi\). That is, it must obtain greater or equal expected return from all states \(s\in S\):
The policy improvement theorem guarantees that if we make the policy greedy with respect to its own value function, the new policy will be at least as good as the original. The new policy \(\pi'\) satisfies \(v_{\pi'}(s) \geq v_\pi(s)\) for all states \(s\).
Intuitively, we’re asking “what if I acted optimally for just one step, then went back to my old policy?” This can only make things better (or stay the same). The greedy policy: $\(\pi'(s) = \arg\max_a \sum_{s'}p(s'|s,a)\left[ r(s,a) + \gamma v_\pi(s')\right]\)$
automatically respects the policy improvement theorem—we’re guaranteed not to make things worse.
Policy Iteration Algorithm#
The complete process alternates between evaluation and improvement until convergence. Since MDPs have a finite number of deterministic policies and each improvement step makes the policy strictly better (unless already optimal), we must eventually reach the optimal policy.
The algorithm cycle is:
1. Start with arbitrary policy π₀
2. EVALUATION: Compute vπ for current policy
3. IMPROVEMENT: Compute improved policy π' from vπ
4. If π' = π, STOP (we found π*)
5. Otherwise, set π = π' and go to step 2
This process will find the optimal policy π* in finite time.
Algorithm 3 (Policy Iteration)
\( \begin{array}{l} \textbf{Inputs}:\\ \quad\quad \theta\ \text{A threshold}\\ \textbf{Initialize}: \\ \quad\quad V(s)\in \mathbb{R}, \text{and}\ \pi(s)\in A\ \text{arbitrarily for all}\ s\in S\\ \ \\ \textbf{2. Policy Evaluation}\\ \textbf{Loop}:\\ \quad\quad \Delta\leftarrow 0\\ \quad\quad \textbf{Foreach}\ s\in S:\\ \quad\quad\quad\quad v \leftarrow V(s)\\ \quad\quad\quad\quad V(s) \leftarrow \sum_a\pi (a|s)\sum_{s'\in S}p(s'|s,a)\left[r + \gamma V(s')\right]\\ \quad\quad\quad\quad \Delta \leftarrow \max (\Delta, |v-V(s)|)\\ \textbf{until}\ \Delta < \theta\\ \ \\ \textbf{3. Policy Improvement}\\ stable\leftarrow true\\ \textbf{Foreach}\ s\in S:\\ \quad\quad old\leftarrow \pi(s) \quad\quad \pi(s)\leftarrow \arg\max_a\sum_{s'}p(s'|s,a)\left[r+\gamma V(s')\right]\\ \quad\quad \textbf{If}\ old \neq \pi(s),\textbf{Then}\ stable\leftarrow false\\ \textbf{If} stable\ \textbf{Then}\ \text{stop, or go to 2.} \end{array} \)
Example
Following the previous example, we can apply policy iteration.
Each evaluation requires multiple sweeps through all states, and we must store value function and policy for all states. The algorithm can be slow for large state spaces.
Activity
Consider the drawbacks: What’s the main computational bottleneck in policy iteration? How might this scale with the size of the state space? Can you think of ways to make it more efficient?
Value Iteration#
Policy iteration’s bottleneck is the full policy evaluation step. What if we combined evaluation and improvement? We don’t need to fully evaluate a policy before improving it—even one step of evaluation gives us useful information for improvement.
Value iteration skips the full policy evaluation step. Instead, it does one step of evaluation combined with immediate improvement, repeating until convergence. Instead of following a fixed policy, we always choose the best action:
While policy iteration says “fully evaluate my current strategy, then improve it,” value iteration says “always act greedily based on my current value estimates.” This approach is more efficient per iteration since there’s no full policy evaluation, but may need more iterations to converge. We continue until value changes are below a threshold.
This approach works because it’s actually solving the Bellman optimality equation directly through iteration.
Algorithm 4 (Value Iteration)
\( \begin{array}{l} \textbf{Inputs}:\\ \quad\quad \pi\ \text{the policy to evaluate}\\ \quad\quad \theta\ \text{A threshold}\\ \textbf{Initialize}: \\ \quad\quad V(s) \in \mathbb{R}, \text{arbitrarily, for all } s \in S,\ \text{except}\ V(terminal)=0 \\ \textbf{Loop}:\\ \quad\quad \Delta\leftarrow 0\\ \quad\quad \textbf{Foreach}\ s\in S:\\ \quad\quad\quad\quad v \leftarrow V(s)\\ \quad\quad\quad\quad V(s) = \max_a \sum_{s'\in S}p(s'|s,a)\left[r + \gamma V(s')\right]\\ \quad\quad\quad\quad \Delta \leftarrow \max (\Delta, |v-V(s)|)\\ \textbf{until}\ \Delta < \theta\\ \textbf{Return}\ \pi(s) = \arg\max_a\sum_{s'}p(s|s,a)\left[r + \gamma V(s')\right]\\ \end{array} \)
Value iteration converges to the optimal value function \(v^*\) and is often faster per iteration than policy iteration, though total computation time depends on the specific problem. It’s simpler to implement since there’s no separate policy evaluation phase, and it’s more memory efficient since we don’t need to store an explicit policy during iteration.
Important
Value iteration often converges faster than policy iteration in terms of wall-clock time, though it may require more iterations.
Once we have \(v^*\), we extract the optimal policy: $\(\pi^*(s) = \arg\max_a\sum_{s'}p(s'|s,a)\left[ r(s,a) + \gamma v^*(s') \right]\)$