Markov Decision Process#
From Bandits to Sequential Decisions#
Remember our multi-armed bandit problem? You learned to balance exploration and exploitation when each action was independent. But what happens when your actions have lasting consequences?
Consider a robot learning to walk—each step affects its balance for the next several steps, where a stumble now impacts future stability. In drug discovery, choosing which molecular modifications to test affects not just immediate results, but the entire research trajectory and available future options. When training large language models, each training decision (learning rate, data selection) influences the model’s capabilities for thousands of future training steps. Similarly, in algorithmic trading, every trade changes your portfolio state, affecting risk profiles and available strategies for subsequent decisions.
These aren’t bandit problems anymore—they’re sequential decision processes where actions have ripple effects through time.
Challenge
Consider training a robot to navigate a research lab. In a bandit setting, the robot chooses “turn left” or “turn right” independently each time. In the real world, turning left now determines where the robot is for its next decision.
How does this fundamental difference change the learning problem? What new challenges emerge?
The Power of MDPs in Modern Applications#
MDPs provide the mathematical backbone for virtually all modern RL breakthroughs. From protein folding prediction to language models, MDPs are everywhere, making the ability to formulate real problems as MDPs a crucial skill.
The progression from simple to complex decision-making follows a clear path: bandits involve independent decisions with immediate rewards, MDPs handle sequential decisions with delayed consequences, and deep RL combines MDPs with neural networks for real-world applications.
MDPs: The Mathematical Foundation#
A Markov Decision Process is a mathematical framework for modeling sequential decision-making under uncertainty. MDPs are sequential (we make multiple decisions over time), consequential (each action affects future situations and opportunities), uncertain (outcomes are probabilistic), and goal-oriented (we’re trying to maximize long-term reward).
Think of planning a road trip where your current location is the state, choosing which road to take is an action, traffic and weather make outcomes uncertain, and you want to minimize total travel time (the reward signal). This everyday scenario captures the essence of why MDPs provide the mathematical foundation for virtually all modern reinforcement learning algorithms.
Important
MDPS involve delayed rewards, so it involves the need to trade off immediate and future rewards.
Activity
How is it different from multi-armed bandit? Think about the key differences in:
State representation
Action consequences
Reward structure
Learning complexity
Reinforcement learning and Markov decision processes are so linked that an MDP is just an idealized form of RL.
In an MDP, we know the problem perfectly and we try to find the optimal solution.
Markov Decision Process Definition#
Markov decision processes formalize how an agent learn to achieve a goal.
The agent can interact with the environment.
The environment comprises everything outside the agent. All the information about the environment is called the state.
When the agent interact with the environment, the environment changes.
The agent will then consider a possible new action depending of the new situation.
It repeats until the problem is solved.
Definition 6 (Markov Decision Process)
Formally, an MDP is defined as a tuple \((S,A,T,R)\):
\(S\) is the finite set of states \(s \in S\) (all possible situations the agent might encounter)
\(A\) is the finite set of actions \(a \in A\) (all choices available to the agent)
\(T: S\times A \times S \rightarrow [0,1]\) is the transition function (the “physics” of how the world changes in response to actions)
\(R: S\times A \rightarrow \mathbb{R}\) is the reward function (immediate feedback that guides learning)
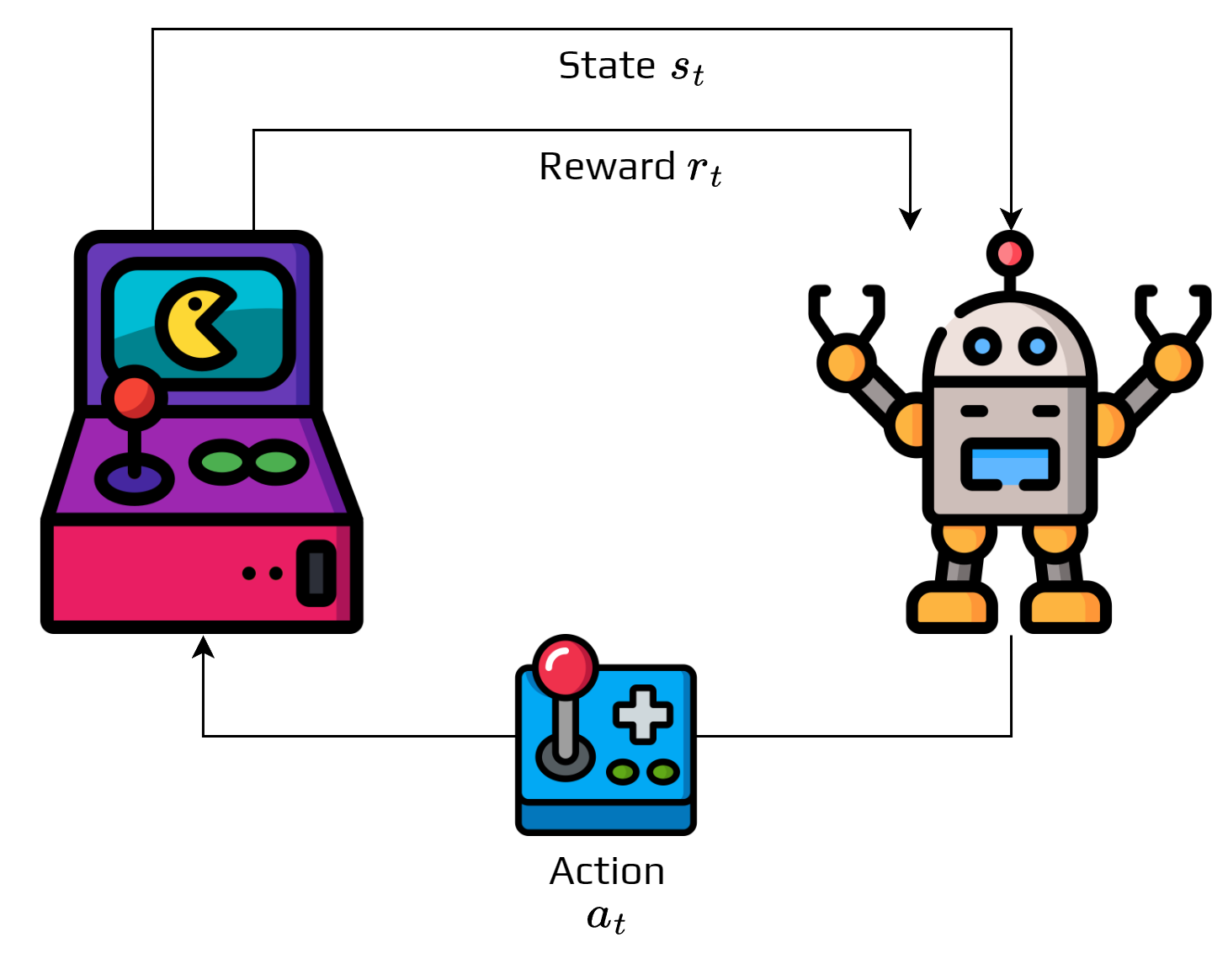
The figure represents the agent-environment interaction.
The interaction follows a simple loop: at time \(t\), the environment is in state \(s_t\), the agent selects an action \(a_t \in A\) based on what it observes, the action is executed, and two things happen—the environment transitions to a new state \(s_{t+1}\) and the agent receives immediate reward \(r_t\). The process then continues from the new state.
This generates a sequence \(s_0, a_0, s_1, a_1, s_2, a_2, \dots\) called a trajectory or episode. Each action has two effects—it gives immediate reward AND changes the situation for future decisions.

Activity
Find a problem that could be represented as a MDP.
Specify how you would define the state and actions.
Transition Function: The World’s Response#
The transition function describes how the world responds to the agent’s actions. After executing action \(a_t\) in state \(s_t\), the next state \(s_{t+1}\) is determined probabilistically:
Real-world actions often have uncertain outcomes—a robot’s motors might have noise, market conditions can change unexpectedly, or experiments may have measurement errors. This probabilistic formulation captures the complete “physics” of how actions change the world.
Note
Remind that for all state \(s\in S\) and actions \(a\in A\) we have:
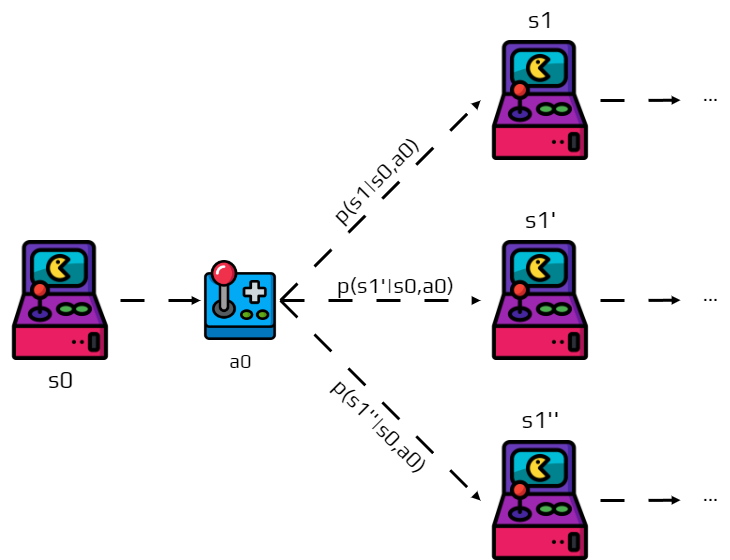
The transition function reveals a crucial assumption about our world called the Markov property. The probability of reaching state \(s'\) depends only on the current state \(s\) and current action \(a\)—not on how we got to state \(s\).
Definition 7 (Markov Property)
The future depends only on the present, not on the past. Formally: all information needed to predict future states must be contained in the current state.
For example, a chess position is Markovian because the complete board state determines possible futures, while an instruction like “take the third turn” is non-Markovian because it depends on path history. This assumption makes MDPs mathematically tractable while still capturing many real-world scenarios.
Activity
Try to explain why this is important for an MDP.
Reward Function: The Learning Signal#
The reward function provides immediate feedback that guides the agent toward its goal. The function \(r(s,a)\) gives the immediate reward for taking action \(a\) in state \(s\).
Rewards are given right after each action and should guide the agent toward the desired behavior, though poor reward design can lead to unintended behaviors. Common examples include robot navigation (\(r = -1\) per step, \(+100\) for reaching goal), game playing (\(r = +1\) for win, \(-1\) for loss, \(0\) otherwise), and resource management (\(r = \text{profit} - \text{cost}\)).
Applications and Research Implications#
This framework’s power lies in its mathematical elegance combined with real-world applicability. Understanding MDPs opens doors to cutting-edge research across multiple domains.
MDP Applications#
Computational Biology & Drug Discovery
State: Current molecular configuration, binding sites, chemical properties
Actions: Add/remove functional groups, modify molecular structure
Reward: Binding affinity, toxicity measures, synthesis complexity
Challenge: Massive state spaces, sparse rewards, safety constraints
Advanced Robotics
State: Joint positions, velocities, environmental perception, task progress
Actions: Motor commands, grasp planning, trajectory selection
Reward: Task completion, energy efficiency, safety margins
Challenge: Continuous spaces, real-time constraints, transfer learning
Large Language Model Training
State: Current model parameters, training data batch, loss landscape
Actions: Learning rate adjustments, architecture modifications, data selection
Reward: Validation performance, computational efficiency, alignment metrics
Challenge: Non-stationary environments, delayed feedback, multi-objective optimization
Research Strategy Optimization
State: Current knowledge, available resources, research progress
Actions: Experiment design, resource allocation, collaboration decisions
Reward: Scientific impact, knowledge gain, progress metrics
Challenge: Extremely long horizons, uncertain outcomes, multi-agent dynamics
Design Challenge
Problem Formulation: Choose a domain and formulate a specific problem as an MDP:
Define the State Space: What information is crucial for decision-making?
Action Space: What decisions can you make? Are they discrete or continuous?
Transition Dynamics: How do your actions change the state? What’s uncertain?
Reward Design: How do you quantify progress toward your goals?
Scalability Issues: What makes this problem computationally challenging?
Reflection: What assumptions does the MDP framework force you to make? Where might it break down?
Why This Framework Matters#
Theoretical Foundation: MDPs provide the mathematical basis for:
Policy gradient methods (used in language model training)
Model-based planning (used in robotics and game AI)
Multi-agent systems (used in economics and distributed AI)
Key Skills: MDP thinking teaches you to:
Formalize complex, sequential decision problems
Identify key state representations for your domain
Design appropriate reward functions
Understand exploration-exploitation trade-offs
Cross-Domain Applications: The same MDP algorithms power:
Autonomous vehicle navigation
Protein folding prediction (AlphaFold)
Resource allocation in cloud computing
Portfolio optimization in quantitative finance
Defining goals and rewards#
We use RL to solve problems, which means we have objectives. But notice something interesting about our MDP definition—nowhere do we explicitly state the goal! Instead of directly programming what we want, we use rewards to communicate our objectives indirectly. We don’t tell the agent “go to the goal location”—instead, we give it positive reward for reaching the goal and let the agent figure out how to maximize total reward.
After each action, the environment sends a reward signal \(r \in \mathbb{R}\), making the agent’s objective “maximize cumulative reward over time.” The designer’s job is to create a reward function that, when maximized, achieves the true goal.
This approach works because it’s flexible (can express complex, multi-faceted objectives), general (same learning algorithm works for vastly different problems), and robust (agent finds novel solutions we might not have considered). However, reward design is an art—the reward function must capture what you really want, not just what’s easy to measure.
Example: Lab Robot Navigation
Consider an autonomous robot in a dynamic laboratory environment:
Goal: Navigate efficiently while avoiding disrupting ongoing experiments
Reward Design Options:
Simple: \(r = -1\) per timestep, \(+100\) for reaching destination
Sophisticated: \(r = -c_1 \cdot time - c_2 \cdot disruption - c_3 \cdot energy + c_4 \cdot progress\)
Question: Which reward function leads to better real-world behavior?
Activity: Reward Engineering
Challenge: For each scenario, design a reward function and identify potential issues:
Training an Assistant AI: Balance task completion with learning new skills
Optimizing Experimental Design: Trade off between expected information gain and resource cost
Planning Strategy: Balance short-term gains with long-term objectives
Questions:
How do you handle multi-objective rewards in practice?
What happens when your reward function doesn’t perfectly capture your true goals?
How might reward hacking emerge in these scenarios?
The agent will maximize the cumulated reward, so we must provide a reward function that if maximized lead to the goal we want.
Activity: Advanced Reward Design
Classical Games:
TicTacToe: What reward function would you use? Why not reward each move?
Chess: What’s wrong with rewarding piece captures? How does this relate to reward hacking?
Applied Scenarios: 3. Scientific Discovery: How would you reward an AI system exploring new chemical compounds? Balance novelty vs. practical utility. 4. Literature Review: Design rewards for an AI assistant helping with research. How do you reward quality vs. quantity? 5. Experimental Design: For an AI choosing which experiments to run, how do you balance information gain vs. resource cost?
Key Considerations:
Temporal Horizons: How do immediate vs. long-term rewards affect different problems?
Reward Shaping: When is it appropriate to add intermediate rewards?
Multi-Objective: How do you handle conflicting objectives (e.g., speed vs. accuracy)?
Important
Fundamental Principle: The reward must communicate what the agent needs to achieve, not how to achieve it.
Key Insight: Poor reward design is often the primary cause of RL failures in applications. The mathematical elegance of MDPs doesn’t solve the fundamental challenge of specifying what we actually want.
Looking Forward: MDP Challenges in Research#
Understanding MDPs opens the door to advanced topics crucial for modern AI research:
Computational Challenges:
Curse of Dimensionality: State spaces grow exponentially
Continuous Spaces: Real-world problems rarely have discrete states/actions
Partial Observability: Perfect state information is often unrealistic
Research Frontiers:
Transfer Learning: How do solutions generalize across problem variants?
Multi-Agent MDPs: What happens when multiple agents interact?
Inverse RL: Can we infer reward functions from observed behavior?
These challenges drive much of current RL research and will be central to your understanding of advanced methods.