Approximation - On-Policy#
The methods seen until now were Tabular Methods.
In these methods we estimate the value \(q_\pi(s,a)\) for each pair state-action. Concretely, Tabular Methods create a big table that contains the value function.
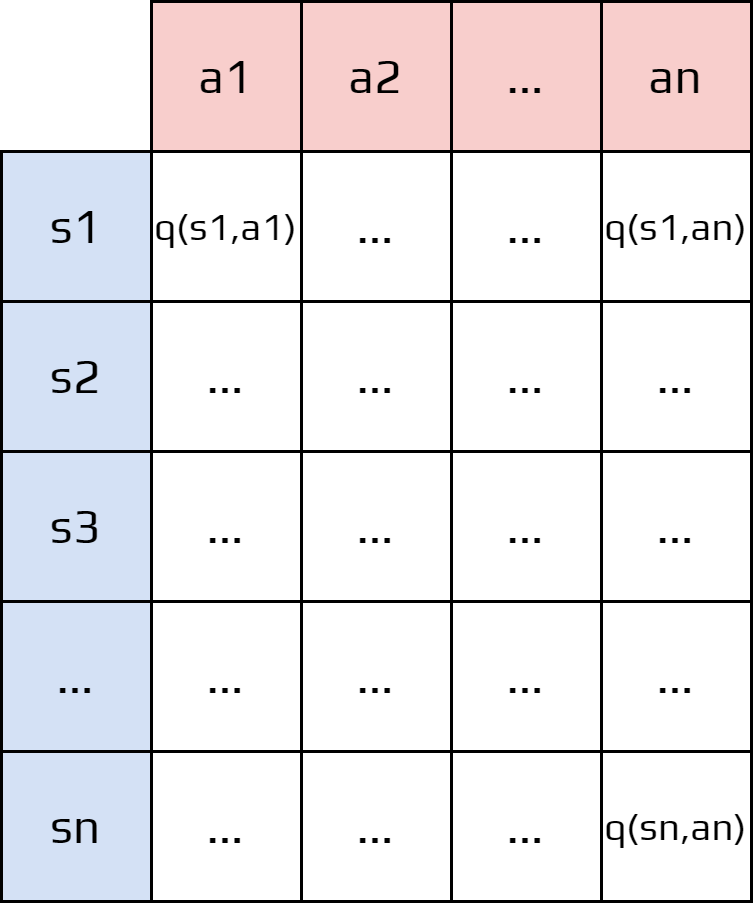
Activity
List some issues that can arise with this type of method.
Value-Function Approximation#
To solve these issues, we will approximate the value function. As the main problem is the table, it needs to be replaced by something smaller. Typically, a weight vector \(\mathbf{w}\in \mathbb{R}^d\).

The approximate value of state \(s\) will be written as \(\hat{v}(s,\mathbf{w})\), so the value of the state is now a function \(\mathbf{w}\).
The vector \(\mathbf{w}\) is common for every state, so we don’t calculate one per state!
The dimension of the \(\mathbf{w}\) is less than the number of states ( \(d \ll |S|\)).
Important
The weight vector being smaller than the state space is how we reduce the complexity.
Before going further, we need to come back on certain terms and notations. During the update, we shifted the value of \(v(s)\) closer to a target.
We can define an individual update by the notation \(s \mapsto u\), where \(s\) is the state and \(u\) the target.
For MC methods: \(s_t \mapsto G_t\).
For TD(0): \(s_t \mapsto r_{t+1} + \gamma\hat{v}(s_{t+1})\)
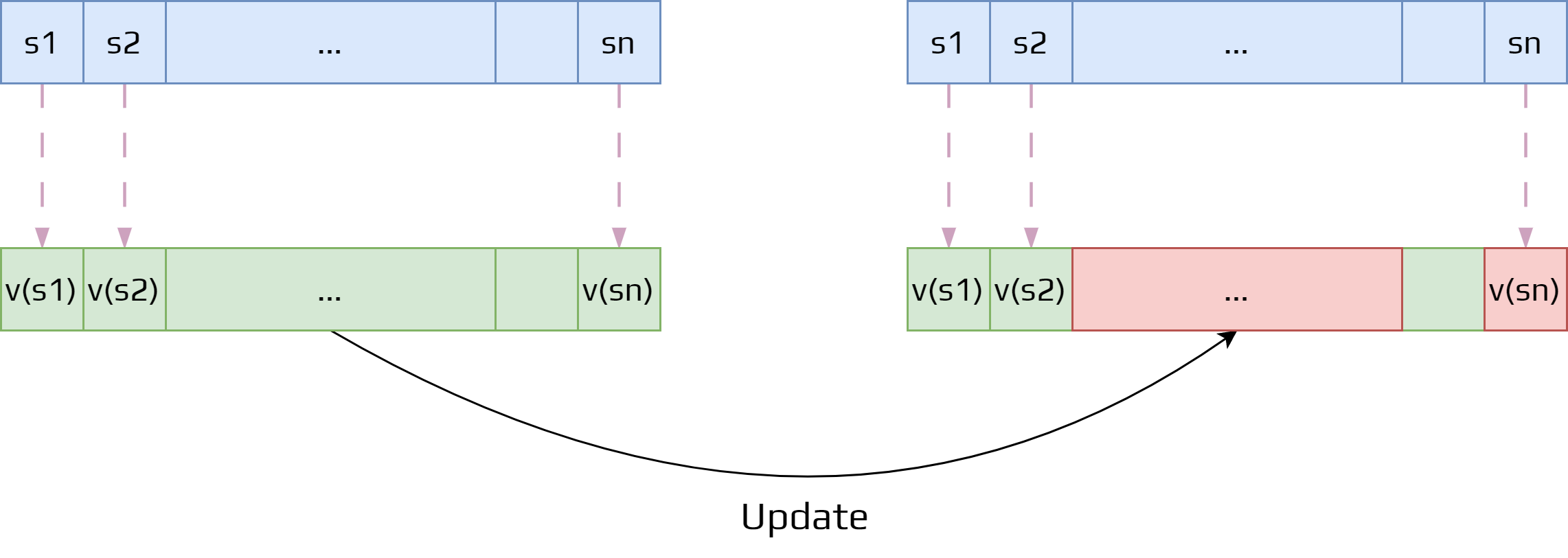
With a weight vector, we can have more complex functions to update the value function.
Note
The weight vector is now calculated using deep neural networks.
Prediction Objective#
Introducing a weight vector smaller than the number of states have certain issues. An update done for one state affects other states, and because it is an approximation it is not possible to get the values of all states.
So making one state’s estimate more accurate invariably means making others’ less accurate.
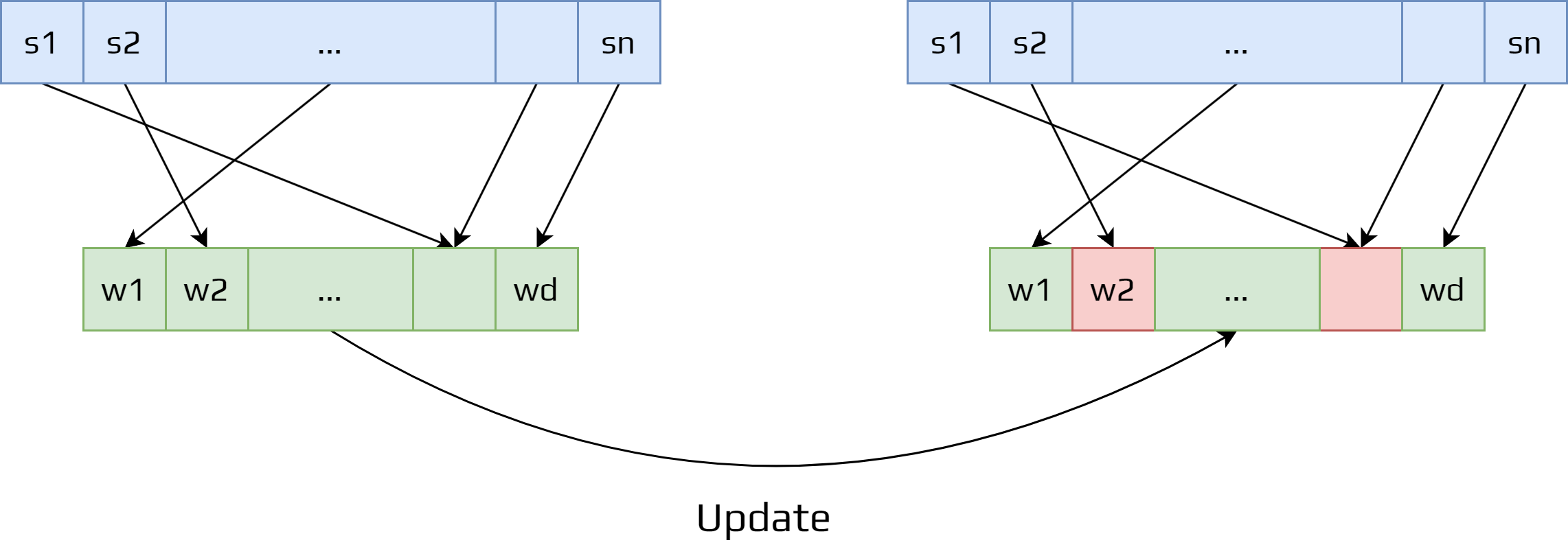
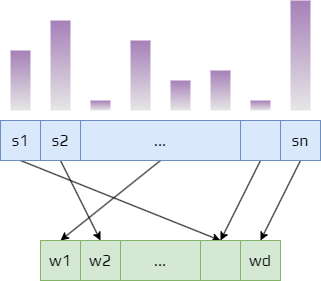
To solve this issue, we need to specify which states are more important. So we create a state distribution: \(\mu (s)\geq 0, \sum_s\mu (s)=1\). States with higher value are more important.
The idea is to reduce the error for these states. The difference between the estimated value \(\hat{v}(s,\mathbf{w})\) and the true value \(v_\pi(s)\).The function is called the mean square value error and is defined as:
Often \(\mu (s)\) is chosen to be a fraction of the time spent in the state \(s\).
This method is called on-policy distribution.
Important
It is not guaranteed that \(\overline{\text{VE}}\) will lead to the global optimum, but usually it converges to a local optimum.
Stochastic-gradient Methods#
It is now time to see in detail the most important class of learning methods for function approximation, the stochastic gradient descent (SGD).
Gradient Descent#
Gradient descent (ascent) algorithm is used to find a local minimum (or maximum) of a function. As we will see, it is very popular in Reinforcement Leaning and Deep Learning.
Important
The main requirement is that the function needs to be differentiable. Meaning that the function has a derivative for each point in its domain.
A gradient is a slope of a curve at a given point in a specified direction.
In the case of a univariate function, it is simply the first derivative at a selected point.
In the case of a multivariate function, it is a vector of derivatives in each main direction (along variable axes).
Because we are interested only in a slope along one axis (and we don’t care about others) these derivatives are called partial derivatives.
Definition 12 (Gradient)
A gradient for an \(n\)-dimensional function \(f(x)\) at a given point \(p\) is defined as follows:
Example 3
Consider a function \(f(x,y) = 0.5 x^2 + y^2\).
Then \(\nabla f(x,y) = \begin{bmatrix}\frac{\partial f(x,y)}{\partial x} \\\frac{\partial f(x,y)}{\partial y} \end{bmatrix} = \begin{bmatrix}x\\ 2y \end{bmatrix}\).
Now if we take \(x = 10\) and \(y = 10\), we obtain \(\nabla f(10,10) = \begin{bmatrix}10\\ 20 \end{bmatrix}\)
Now, we can calculate the gradient (the slope), we can try to find the minimum point. The gradient descent algorithm just calculates iteratively the next point using:
with \(\eta\) being the learning rate. The algorithm stops when the step size \(\eta\nabla f(p_n)\) is less than a tolerance.
import numpy as np
def gradient_descent(start, gradient, learn_rate, max_iter, tol=0.01):
steps = [start] # history tracking
x = start
for _ in range(max_iter):
diff = learn_rate * gradient(x)
if np.abs(diff) < tol:
break
x = x - diff
steps.append(x) # history tracing
return steps, x
Activity
Calculate gradient function of \(f(x) = x^2 - 4x + 1\).
Execute three steps of the gradient descent algorithm starting with \(x=9\) and \(\eta=0.1\).
Stochastic-Gradient methods in RL#
In gradient-descent methods:
The weight vector is a column vector \(\mathbf{w} = (w_1, w_2,\dots,w_d)^\intercal\).
The approximate value function \(\hat{v}(s,\mathbf{w})\) is a differentiable function of \(\mathbf{w}\) for all \(s\in S\).
Assumption 2
At each step we observe \(s_t \mapsto v_\pi(s_t)\), a state and its true value under \(\pi\).
States appear with the same distribution \(\mu\) we are trying to minimize the \(\overline{\text{VE}}\):
We could try to do it on the sample observed:
where \(\alpha\) is a positive step-size, and \(\nabla f(\mathbf{w})\) denotes the vector of partial derivatives:
It is called a gradient descent method, because the step in \(\mathbf{w}_t\) is proportional to the negative gradient of the squared error. And it is said stochastic when it’s done on a single state that is chosen stochastically.
Estimating the weight vector#
Usually, we don’t observe the true value of a state \(v_\pi (s)\), but we have an approximate value \(U_t\) at time \(t\).
If \(U_t\) is an unbiased estimate, then we can rewrite the previous equation:
Example 4 (Gradient-descent Monte-Carlo)
Now if we consider a Monte-Carlo approach, we don’t observe the true value of a state but we simulate interaction with the environment.
It gives an expected return \(G_t\) which is unbiased, so we can say that \(U_t = G_t\); letting us apply the gradient descent.
Algorithm 12 (Gradient descent for Monte-Carlo)
\( \begin{array}{l} \textbf{Inputs}:\\ \quad\quad \pi\ \text{the policy to be evaluated}\\ \quad\quad N\ \text{the number of episodes}\\ \quad\quad \alpha\in 0, 1\ \text{the step size}\\ \textbf{Initialize}: \\ \quad\quad \mathbf{w}\in \mathbb{R}^d\ \text{arbitrarily, e.g.,} \mathbf{w}=\mathbf{0}.\\ \textbf{Repeat}\ \text{for}\ N\ \text{episodes:}\\ \quad\quad \text{Generate an episode using } \pi: S_0, A_0, R_1, S_1, R_2, \dots, S_{T-1}, A_{T-1}, R_T\\ \quad\quad \textbf{Repeat}\ \text{for each step}\ t = 0, 1, \dots, T-1\\ \quad\quad\quad\quad \mathbf{w} \leftarrow \mathbf{w} + \alpha \left[ G_t - \hat{v}(s_t,\mathbf{w}) \right]\nabla\hat{v}(s,\mathbf{w}) \end{array} \)
TD using approximation is a semi-gradient method, it converges to the local optimal, but not as fast. In the case of TD(0), we have \(U_t = r_{t+1} + \gamma\hat{v}(s_{t+1},\mathbf{w})\) as the target.
Algorithm 13 (Semi-gradient TD(0))
\( \begin{array}{l} \textbf{Inputs}:\\ \quad\quad \pi\ \text{The policy to be evaluated}\\ \quad\quad \hat{v}\in \mathcal{S}^+\times\mathbb{R}^d\rightarrow\mathbb{R}, \text{such that}\ \hat{v}(\text{terminal},.) = 0 \\ \quad\quad N\ \text{the number of episodes}\\ \quad\quad \alpha\in ]0, 1]\ \text{the step size}\\ \textbf{Initialize}: \\ \quad\quad \mathbf{w}\in \mathbb{R}^d\ \text{arbitrarily, e.g.,} \mathbf{w}=\mathbf{0}.\\ \textbf{Repeat}\ \text{for}\ N\ \text{episodes:}\\ \quad\quad \textbf{Intialize}\ s\\ \quad\quad \textbf{Repeat}\ \text{for each step until} s=terminal:\\ \quad\quad\quad\quad a\leftarrow \pi (.|s)\\ \quad\quad\quad\quad r, s' \leftarrow \text{Execute a}\\ \quad\quad\quad\quad \mathbf{w} \leftarrow \mathbf{w} + \alpha \left[ r + \gamma\hat{v}(s',\mathbf{w}) - \hat{v}(s_t,\mathbf{w}) \right]\nabla\hat{v}(s,\mathbf{w})\\ \quad\quad\quad\quad s\leftarrow s'\\ \end{array} \)
On-policy Control#
Until now, we saw how to estimate the error function based on a given policy \(\pi\). To take into account the vector of weight \(\mathbf{w}\) we can rewrite of q-function from \(q^*(s,a)\) to \(\hat{q}(s,a,\mathbf{w})\).
We can extend SARSA to semi-gradient methods, the main difference with policy estimation is that use \(\mathbf{w}\) for the q-function. We define the gradient-descent update for action-value as:
where \(U_t\) can be any approximation of \(q_\pi(s_t,a_t)\).
In our case, we are interested in the one-step Sarsa algorithm, so we can rewrite it as:
The idea for the algorithm is simple:
For each possible action \(a\), compute \(\hat{q}(s_{t+1}, a, \mathbf{w}_t)\).
Find the greedy action \(a^*_{t+1}=\arg\max_a\hat{q}(s_{t+1}, a, \mathbf{w}_t)\).
The policy improvement is done by changing the estimation policy to a soft approximation of the greedy policy such as \(\epsilon\)-greedy policy.
Algorithm 14 (Semi-gradient Sarsa)
\( \begin{array}{l} \textbf{Inputs}:\\ \quad\quad \hat{q}\in \mathcal{S}\times\mathcal{A}\times\mathbb{R}^d\rightarrow\mathbb{R}\\ \quad\quad N\ \text{the number of episodes}\\ \quad\quad \epsilon > 0 \quad\quad \alpha\in ]0, 1]\ \text{the step size}\\ \textbf{Initialize}: \\ \quad\quad \mathbf{w}\in \mathbb{R}^d\ \text{arbitrarily, e.g.,} \mathbf{w}=\mathbf{0}.\\ \textbf{Repeat}\ \text{for}\ N\ \text{episodes:}\\ \quad\quad \textbf{Intialize}\ s\\ \quad\quad a\leftarrow \hat{q}(s,.,\mathbf{w})\ \text{(using }\epsilon\text{-greedy)}\\ \quad\quad \textbf{Repeat}\ \text{for each step until}\ s=terminal:\\ \quad\quad\quad\quad \textbf{If}\ s' = terminal\\ \quad\quad\quad\quad\quad\quad \mathbf{w} = \mathbf{w} + \alpha\left[ R - \hat{q}(s,a,\mathbf{w}_t) \right] \nabla\hat{q}(s,a,\mathbf{w}_t)\\ \quad\quad\quad\quad\quad\quad \textbf{break}\\ \quad\quad\quad\quad a'\leftarrow \hat{q}(s,.,\mathbf{w})\ \text{(using }\epsilon\text{-greedy)}\\ \quad\quad\quad\quad r, s' \leftarrow \text{Execute a}\\ \quad\quad\quad\quad \mathbf{w} \leftarrow \mathbf{w} + \alpha \left[ r + \gamma\hat{q}(s',a',\mathbf{w}) - \hat{q}(s_t,a,\mathbf{w}) \right]\nabla\hat{v}(s,a,\mathbf{w})\\ \quad\quad\quad\quad s\leftarrow s'\\ \quad\quad\quad\quad a\leftarrow a'\\ \end{array} \)
Function Approximation#
We said that \(\mathbf{w}\in \mathbb{R}^d\) of dimension smaller that the number of states, so it means that we don’t have a direct mapping from \((s,a)\mapsto q_\pi(s,a)\).
We need a function approximation for \(\hat{v}(.,\mathbf{w})\). Troughout the litterature you can find different methods:
State-aggregation
Linear function
Neural networks
Etc.
State-aggregation#
It is the simplest one, as you split the states in groups that should be similar enough. Then the value function will assign the same value for the states in the same group.
It works for very simple problems, but it becomes limited very quickly.
Linear Function#
One of the most important special cases of function approximation. The approximate function \(\hat{v}(.,\mathbf{w})\) is a linear function of \(\mathbf{w}\). Concretely, for every state \(s\), there is a real-valued vector \(\mathbf{x}(s) = (x_1(s0), x_2(s),\dots, x_d(s))^T\).
Linear methods approximate the state-value function by the inner product between \(\mathbf{w}\) and \(\mathbf{x}(s)\):
The vector \(\mathbf{x}(s)\) is called a feature vector representing state \(s\).
It is useful in stochastic gradient descent, because the gradient is simply:
Meaning the update in the linear case, just becomes:
Feature Construction for Linear Methods#
Linear methods are powerful and efficient, but they depend mainly on how the states are represented in terms of features. A limitation of the linear form is that it cannot take into account any interactions between features.
Activity
Give some examples of problems where we would like to know the interaction of two features.
We would need the combination of these two features in another feature. Polynomial functions are a simple way to do that.
Example 5 (Polynomial functions)
Suppose a reinforcement learning problem has states with two numerical dimensions. A state will be represented by two values: \(s_1\in \mathbb{R}\) and \(s_2\in \mathbb{R}\).
You could be tempted to use a 2D feature vector \(\mathbf{x}(s) = [s_1, s_2]^T\).
With this representation the interaction between \(s_1\) and \(s_2\) cannot be represented.
Also, if \(s_1 = s_2 = 0\), the approximation would always be 0.
It can be solved by adding some features: \(\mathbf{x}(s) = [1, s_1, s_2, s_1s_2]^T\), or even add more dimensions: \(\mathbf{x}(s) = [1, s_1, s_2, s_1s_2, s_1^2,s_2^2,s_1^2s_2,s_1s_2^2,s_1^2s_2^2]^T\).