13. Partially Observable Markov Decision Process
Markov Decision Processe (MDP) is a good framework for control decision when the measurement is perfect.
However, most of the time the measurement is not perfect.
To address the uncertainty on the measurement a new framework was created: Partially Observable Markov Decision Process (POMDP)
13.1. How does it work?
In MDPs, we use the value iteration function:
However, in POMDPs we don’t know what the state \(s\) is.
In robotics we use the notion of belief state \(b\).
If we replace \(s\) by \(b\) in the previous equation we obtain:
Giving us the control policy:
The issue with using the belief state is that it is continuous.
Important
When the state space, the action space, the space of observations and the planning horizon are all finite there is a solution.
Example
We will consider the following problem represented as a POMDP.
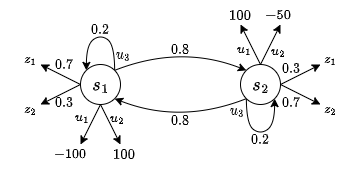
The actions \(u_1\) and \(u_2\) are giving different rewards depending of the states.
Only \(u_3\) is giving the same one: \(-1\).
The goal of the robot is to use \(u_3\) to gain information of the real state.
13.1.1. Action selection
Before solving the problem we need to have a way to calculate the reward for a specific action.
For any belief state \(b = (p_1, p_2)\), the expected reward us calculated as:
which gives use the following expected rewards:
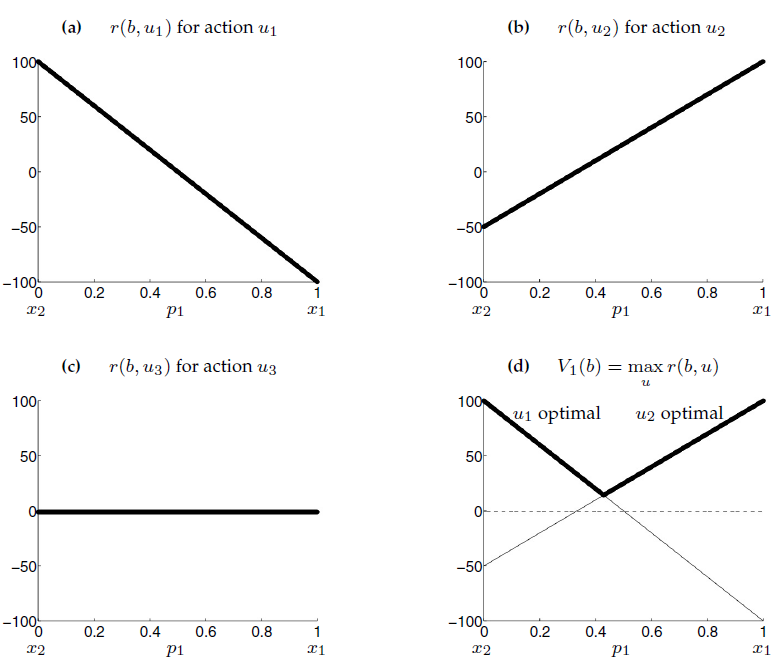
Important
Even with two states calculating the expected reward is complex.
Also the we can see the expected value function is piecewise linear and convex!
Activity
Calculate the expected reward for the following belief states and every actions:
\(b_1 = (0.3, 0.7)\)
\(b_2 = (0.5, 0.5)\)
\(b_3 = (0.7, 0.3)\)
Calculating the best action at one time step is solving a set of linear equations:
As only the first two linear functions contribute to the optimal action we can prune the third one:
Note
Prunable functions are usually represented by dashed lines.
13.1.2. Sensing
We suppose now that we receive a measurement \(z_1\).
We can apply Bayes rule:
For \(p_1\):
\[\begin{split}\begin{aligned} p_1' &= p(x_1|z)\\ &= \frac{p(z_1|x_1)p(x_1)}{p(z_1)}\\ &= \frac{0.7p_1}{p(z_1)} \end{aligned}\end{split}\]For \(p_2\):
\[\begin{aligned} p_2' &= \frac{0.3(1-p_1)}{p(z_1)} \end{aligned}\]The only issue is the normalizer \(p(z_1)\):
If we use the measurement, our belief becomes nonlinear:
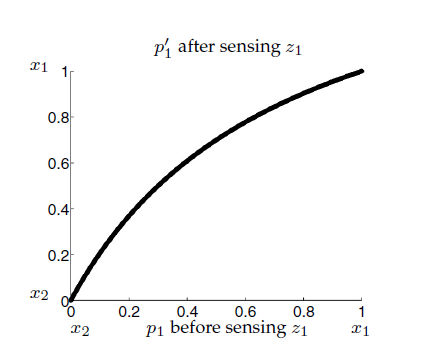
Changing the expected value:
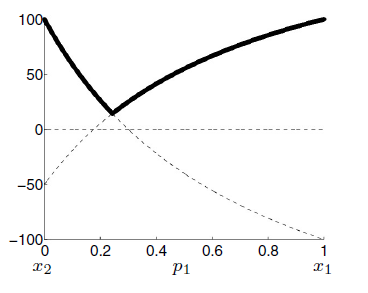
Mathematically:
This is only considering one measurement.
We need to calculate the value before sensing for every measurement:
However, \(v_1(b|z_i)\) is conditioned to \(p(z_i)\):
Important
The nonlinearity cancels out!
It allow us to calculate:
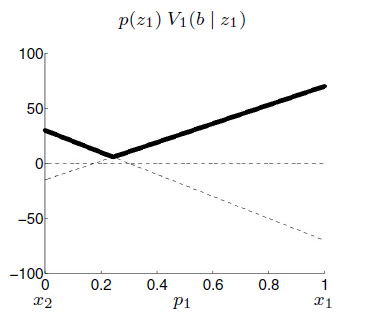
Same for \(z_2\):
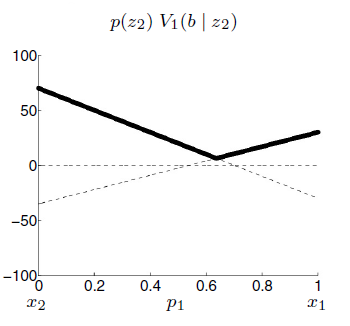
So the value function before sensing becomes:
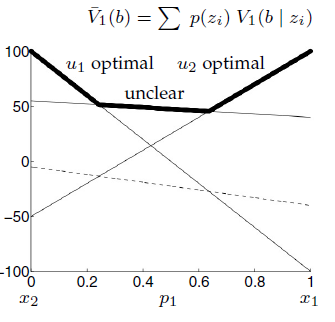
However, it seems easier that it is.
We actually need to compute the maximum between any sums that adds a linear function from the previous expression.
Which leaves us with four possible combination:
13.1.3. Prediction
Now we need to deal with the state transition.
Consider we start in \(s_1\) with a probability of \(p_1 = 1\).
Then based on our model:
\[p_1' = p(s_1'|s_2',u_3) = 0.2\]Similarly if \(p_1 = 0\)
\[p_1' = p(s_1'|s_2',u_3) = 0.8\]And in between the expectations is linear:
Which give us:
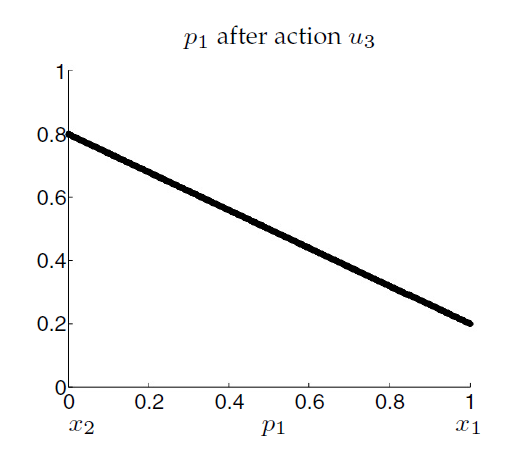
If we project this to our previous value function \(\bar{v_1}(b)\).
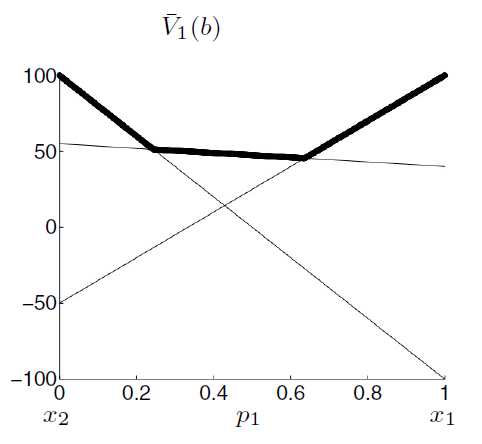
We obtain:

We can see it flattens, because we lose information.
Mathematically it’s the projection of \(p_1'\) through \(\bar{v_1}(b)\), giving us:
The value function for step \(T=2\).
We just add \(u_1\) and \(u_2\).
We remove the uniform cost od \(-1\) from \(u_3\).
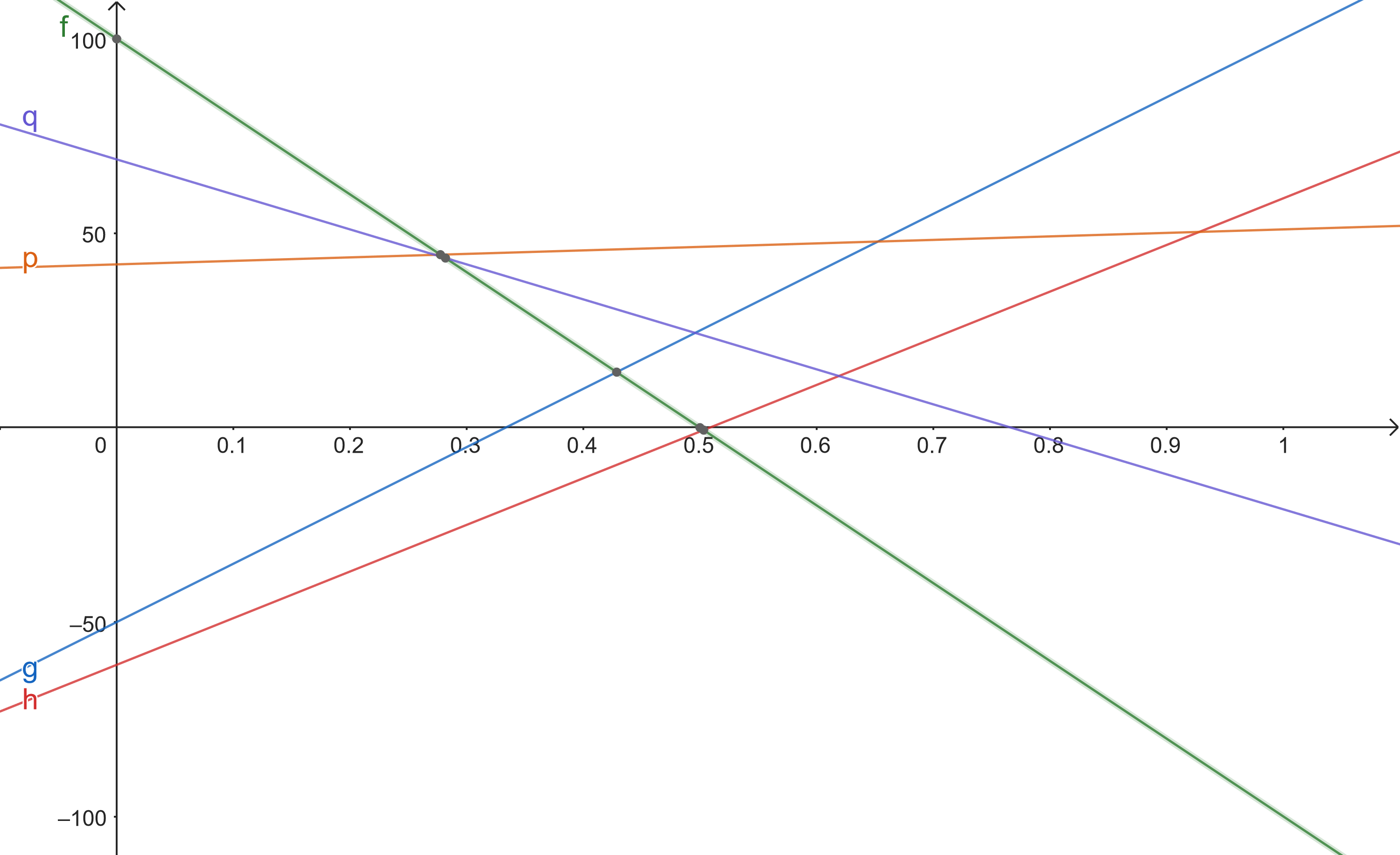
We can prune two functions are suboptimal.
Important
We have done a full backup!